本文转载自“数据库架构之美”公众号 冻结(FREEZE),相信熟悉pg的人都对这个词不陌生,因为冻结过程对数据库的资源消耗极大,影响业务的正常运行,所以也被称为“冻结炸弹”。网上关于冻结的文章也比较多,本文就系统性的介绍一下冻结过程的原理以及如何预防。
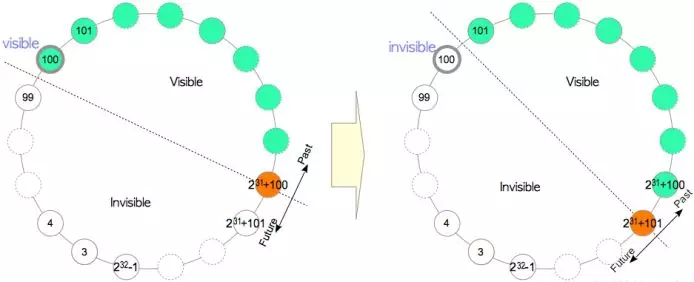
事务号回卷问题 先介绍下事务号回卷的问题,这也是为什么需要冻结的根本原因。我们知道,postgresql数据库使用32位事务号,最大容纳42亿左右的事务号,事务号是循环使用的,当事务号耗尽后又会从3开始循环使用。事务环被分为两个半圆,当前事务号过去的21亿事务属于过去的事务号,当前事务号往前的21亿属于未来的事务号,未来的事务号对当前事务是不可见的。
如上图所示,当前事务号走到了+100,由txid=100的事务号创建的元组(元组的xmin=100)对于当前事务属于过去来说是可见的,当下一个事务+101开启时,该元组就变为未来的事务号了,该元组就变为了不可见。为了解决这个问题,pg引入了冻结事务id的概念,并使用freeze过程实现旧事务号的冻结。
Postgresql有三个特殊事务号:0代表无效事务号;1表示数据库集群初始化的事务id,也就是在执行initdb操作时的事务号;2代表冻结事务id。Txid=2的事务在参与事务id比较时总是比所有事务都旧,冻结的txid始终处理非活跃状态,并且始终对其他事务可见。
如果发生当新老事务id差超过21亿的时候,事务号会发生回卷,此时数据库会报出如下错误并且拒绝接受所有连接,必须进入单用户模式执行vacuum freeze操作。
ERROR: database is not accepting commands to avoid wraparound data loss in database "xxdb"
HINT: Stop the postmaster and vacuum that database in single-user mode
所以冻结过程应该在平时不断地自动做而不是等到事务号需要回卷的时候才去做。这时就需要引入一个参数:vacuum_freeze_min_age(默认5000万),当冻结过程在扫描表页面元组的时候发现元组xmin比当前事务号current_txid-vacuum_freeze_min_age更小时,就可以将该元组事务id置为2,换个角度理解,也就是对于当前事务来说,如果存在某个元组的事务年龄超过vacuum_freeze_min_age参数值时,就可以在vacuum时把该元组事务号冻结。冻结会将元组结构体中的t_infomask字段置为XMIN_FROZEN(我之前有一篇讲HOT技术的文章讲到了元组结构)。
可见性映射VM 可见性映射VM和vacuum有关,vacuum是一个比较消耗资源的操作,为了提高vacuum的效率,让vacuum只扫描存在死元组的页面,而跳过全部都是活跃元组的页面,设计了VM数据结构。在数据base目录,每个表都存在一个对应的vm文件,vm由若干个8k页面组成,类似一个数组结构,记录了该表各个页面上是否包含死亡元组信息。VM结构如下:
在9.6以后的版本中,针对冻结过程,vm的功能进行了增强,vm中除了记录死亡元组信息,还记录了页面元组的冻结标识信息。如果页面所有元组都已经被冻结,则置vm中的冻结标识为1,freeze操作就会跳过该页面,提升效率。
冻结过程FREEZE 冻结有两种模式,懒惰模式(lazy mode)和急切模式(eager mode)。他们之间的区别在于懒惰模式是跟随者普通vacuum进程进行的,只会扫描包含死元组的页面,而急切模式会扫描所有页面(当然9.6之后已经优化),同时更新相关系统视图frozenxid信息,并且清理无用的clog文件。
在冻结开始时,postgresql会计算freezelimit_txid的值,并冻结xmin小于freezelimit_txid的元组,freezelimit_txid的计算前面也提到过,freezelimit_txid=oldestxmin-vacuum_freeze_min_age,vacuum_freeze_min_age可以理解为一个元组可以做freeze的最小间隔年龄,因为事务回卷的问题,这个值最大设置为20亿,oldestxmin代表当前活跃的所有事务中的最小的事务标识,如果不存在其他事务,那oldestxmin就是当前执行vacuum的事务id。普通vacuum进程会挨个扫描页面,同时配合vm可见性映射跳过不存在死元组的页面,将xmin小于freezelimit_txid的元组t_infomask置为XMIN_FROZEN,清理完成之后,相关统计视图中n_live_tuple、n_dead_tuple、vacuum_count、autovacuum_count、last_autovacuum、last_vacuum之类的统计信息会被更新。
普通的vacuum只会扫描脏页,而freeze操作会扫描所有可见且没有被全部冻结的页面,所以在每次vacuum时都去扫描是不合适的。这时就有了急切冻结模式,急切冻结引入一个参数vacuum_freeze_table_age,同理该参数的最大值也只能是20亿,当表的年龄大于vacuum_freeze_table_age时,会执行急切冻结,表的年龄通过oldestxmin-pg_class.relfrozenxid计算得到,pg_class.relfrozenxid字段是在某个表被冻结后更新的,代表着某个表最近的冻结事务id。而pg_database.relfrozenxid代表着当前库所有表的最小冻结标识,所以只有当该库具有最小冻结标识的表被冻结时,pg_database.relfrozenxid字段才会被更新。急切冻结的触发条件是pg_database.relfrozenxid<oldestxmin-vacuum_freeze_table_age,这其实和上面的说法不冲突,因为某个数据库所有表中的最老的relfrozenxid就是数据库的relfrozenxid,所以冻结可以用一句话来理解:当数据库中存在某个表的年龄大于vacuum_freeze_table_age参数设定值,就会执行急切冻结过程,当表中元组年龄超过vacuum_freeze_min_age,就可以被冻结,这里其实是必须和可以的区别。
最佳实践 Freeze是运维好pg数据库必须要十分关注的点。关于freeze有如下三个参数:vacuum_freeze_min_age、vacuum_freeze_table_age、autovacuum_freeze_max_age。前两个参数其实前面介绍的差不多了,感觉这两个参数已经足够了,那么为什么需要第三个参数呢?
下面我们这样假设:vacuum_freeze_min_age=2亿,vacuum_freeze_table_age=19亿,那么只有当表中元组年龄达到2亿时才可以执行freeze操作,这其中部分元组id被置为冻结,部分没有被冻结,同时更新表的relfrozenxid为2亿,然后假设我们从2亿开始表的年龄又过了19亿,这时候表的年龄达到了,这时候会强制执行急切冻结,但是此时新老事务号差距已经达到了21亿,超过了20亿的限制,从另一个角度理解,vacuum_freeze_min_age是相当于在年龄线上增加了一段长度,而且必须有这段长度才能执行freeze操作,这样就不能保证vacuum_freeze_table_age+vacuum_freeze_min_age<20亿,此时就需要单独弄一个参数来保证新老事务差不超过20亿,这个参数就是autovacuum_freeze_max_age。这个参数会强制限制元组的年龄(oldestxmin-xmin)如果超过该值就必须进行急切冻结操作,这个限制是个硬限制。
针对生产环境中,有如下建议:
①autovacuum_freeze_max_age的值应该大于vacuum_freeze_table_age的值,因为如果反过来设置,那么每次当表年龄vacuum_freeze_table_age达到时,autovacuum_freeze_max_age也达到了,那么刚刚做的freeze操作又会去扫描一遍,造成浪费。但是vacuum_freeze_table_age的值也不能太小,太小的话会造成频繁的急切冻结。
②执行急切冻结时,vacuum_freeze_table_age真正的值会去取vacuum_freeze_table_age和0.95autovacuum_freeze_max_age中的较小值,所以官方建议将vacuum_freeze_table_age设置为0.95 autovacuum_freeze_max_age。
③autovacuum_freeze_max_age和vacuum_freeze_table_age的值也不适合设置过大,因为过大会造成pg_clog中的日志文件堆积,来不及清理。
④vacuum_freeze_min_age不易设置过小,比如我们freeze某个元组后,这个元组马上又被更新,那么之前的freeze操作其实是无用功,freeze真正应该针对的是那些长时间不被更新的元组。
⑤生产环境中做好pg_database.frozenxid的监控,当快达到触发值时,我们应该选择一个业务低峰期窗口主动执行vacuum freeze操作,而不是等待数据库被动触发。
.png)