Bhuvanesh2019-12-20295摘要:我们生活在DataLake世界中。几乎每个公司都希望其报告接近实时。Kafka是用于实时报告的最佳流媒体平台。RedHat基于Kafka连接器,设计了Debezium,这是一种开源产品,强烈推荐用于跨国数据库的实时CDC。
我们生活在DataLake世界中。现在,几乎每个公司都希望其报告接近实时。Kafka是用于实时报告的最佳流媒体平台。RedHat基于Kafka连接器,设计了Debezium,这是一种开源产品,强烈推荐用于跨国数据库的实时CDC。我发现设置此集群只是基本的安装步骤,因此,我为具有生产级的AWS设置了该集群,请查看下文。
简介:
Debezium是一组分布式服务,用于捕获数据库中的更改,以便您的应用程序中可以查看这些更改并对它们做出响应。Debezium在更改事件流中记录每个数据库表中的所有行级更改,应用程序只需读取这些流,即可按发生事件的顺序查看更改事件。
基本技术术语:
- Kafka经纪人:经纪人是kafka流媒体的核心,他们会保留您的消息并将其传递给消费者。
- Zookeeper:它将维护集群状态和节点状态。这将有助于提高Kafka的可用性。
- 生产者:将消息(数据)发送到代理的组件。
- 使用者:将从队列中获取消息以进行进一步分析的组件。
- Confluent: Confluent有自己的蒸平台,基本上在后台使用Apache Kafka。但是它具有更多功能。
在这里,Debezium是我们的数据生产者,而S3sink是我们的消费者。对于此设置,我将使用自定义格式将MySQL数据更改流式传输到S3。
AWS架构:
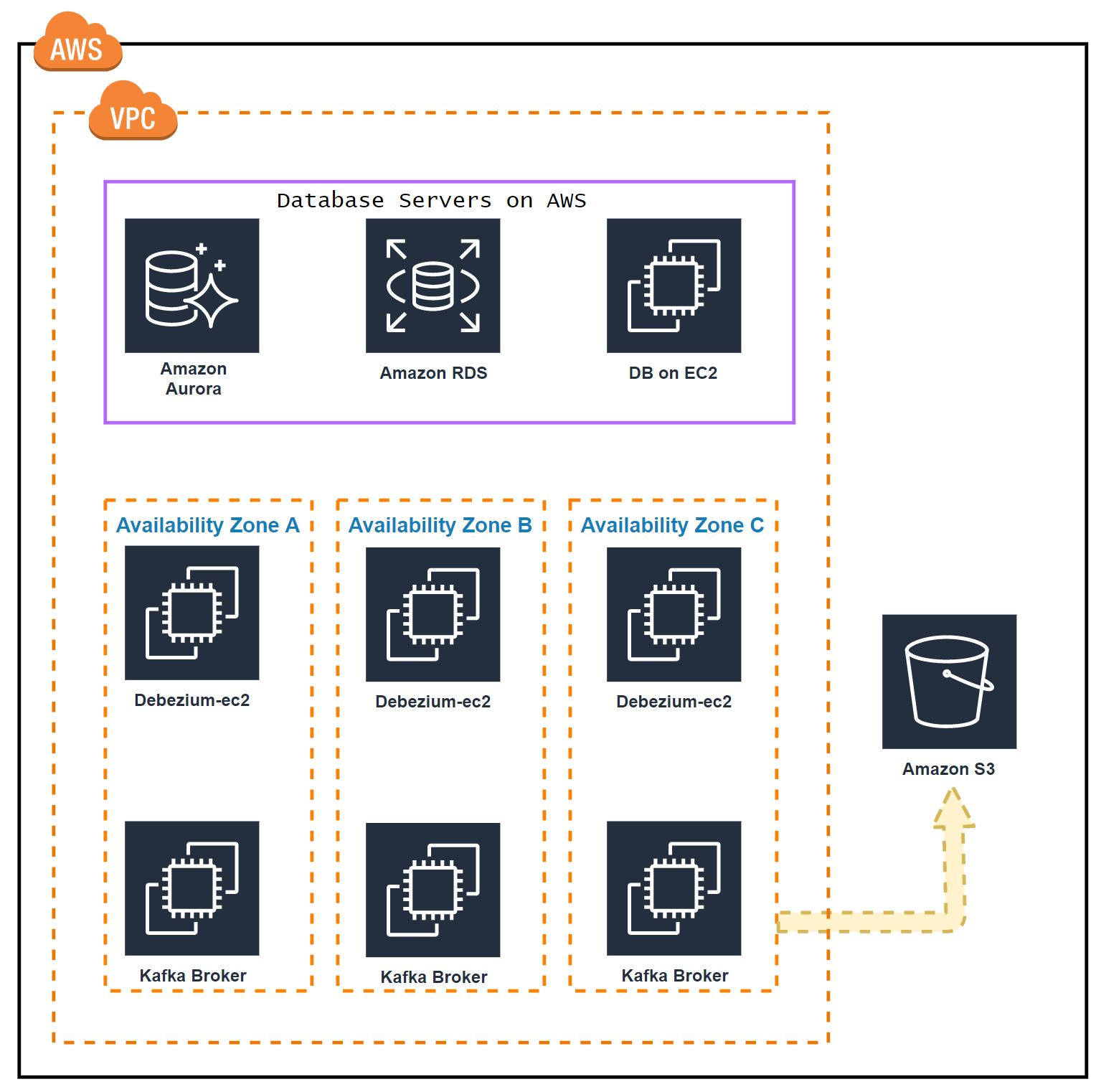
Kafka和Zookeepers安装在同一EC2上。我们将部署3个节点融合的Kafka集群。每个节点将位于不同的可用区中。
- 172.31.47.152-A区
- 172.31.38.158-B区
- 172.31.46.207-C区
对于Producer(debezium)和Consumer(S3sink)将托管在同一Ec2上。我们将为此设置3个节点。 - 172.31.47.12-A区
- 172.31.38.183-B区
- 172.31.46.136-C区
实例类型:
Kafka节点通常需要内存和网络优化。您可以选择持久存储和临时存储。我更喜欢Kaska存储的永久SSD磁盘。因此,将n GB大小的磁盘添加到您的Kafka代理节点。对于正常工作负载,最好使用R4实例系列。
将卷安装到位/kafkadata。
安装:
在所有Broker节点上安装Java和Kafka。
-- Install OpenJDK
apt-get -y update
sudo apt-get -y install default-jre
-- Install Confluent Kafka platform
wget -qO - https://packages.confluent.io/deb/5.3/archive.key | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://packages.confluent.io/deb/5.3 stable main"
sudo apt-get update && sudo apt-get install confluent-platform-2.12
配置:
我们需要配置Zookeeper和Kafaka属性,/etc/kafka/zookeeper.properties在所有kafka节点上编辑
-- On Node 1
dataDir=/var/lib/zookeeper
clientPort=2181
maxClientCnxns=0
server.1=0.0.0.0:2888:3888
server.2=172.31.38.158:2888:3888
server.3=172.31.46.207:2888:3888
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
initLimit=5
syncLimit=2
-- On Node 2
dataDir=/var/lib/zookeeper
clientPort=2181
maxClientCnxns=0
server.1=172.31.47.152:2888:3888
server.2=0.0.0.0:2888:3888
server.3=172.31.46.207:2888:3888
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
initLimit=5
syncLimit=2
-- On Node 3
dataDir=/var/lib/zookeeper
clientPort=2181
maxClientCnxns=0
server.1=172.31.47.152:2888:3888
server.2=172.31.38.158:2888:3888
server.3=0.0.0.0:2888:3888
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
initLimit=5
syncLimit=2
我们需要为所有Zookeeper节点分配一个唯一的ID。
-- On Node 1
echo "1" > /var/lib/zookeeper/myid
--On Node 2
echo "2" > /var/lib/zookeeper/myid
--On Node 3
echo "3" > /var/lib/zookeeper/myid
现在我们需要配置Kafka代理。因此,请/etc/kafka/server.properties在所有kafka节点上进行编辑。
--On Node 1
broker.id.generation.enable=true
delete.topic.enable=true
listeners=PLAINTEXT://:9092
zookeeper.connect=172.31.47.152:2181,172.31.38.158:2181,172.31.46.207:2181
log.dirs=/kafkadata/kafka
log.retention.hours=168
num.partitions=1
--On Node 2
broker.id.generation.enable=true
delete.topic.enable=true
listeners=PLAINTEXT://:9092
log.dirs=/kafkadata/kafka
zookeeper.connect=172.31.47.152:2181,172.31.38.158:2181,172.31.46.207:2181
log.retention.hours=168
num.partitions=1
-- On Node 3
broker.id.generation.enable=true
delete.topic.enable=true
listeners=PLAINTEXT://:9092
log.dirs=/kafkadata/kafka
zookeeper.connect=172.31.47.152:2181,172.31.38.158:2181,172.31.46.207:2181
num.partitions=1
log.retention.hours=168
下一步是优化Java JVM Heap大小。在许多地方,由于堆大小较小,kafka将会下降。因此,我将50%的内存分配给堆。但是请确保更多的堆大小也很糟糕。请参考一些文档以为非常重的系统设置该值。
vi /usr/bin/kafka-server-start
export KAFKA_HEAP_OPTS="-Xmx2G -Xms2G"
kafka系统中的另一个主要问题是打开文件描述符。因此,我们需要允许kafka至少打开100000个文件。
vi /etc/pam.d/common-session
session required pam_limits.so
vi /etc/security/limits.conf
* soft nofile 10000
* hard nofile 100000
cp-kafka soft nofile 10000
cp-kafka hard nofile 100000
这里cp-kafka是kafka进程的默认用户。
创建Kafka数据目录:
mkdir -p /kafkadata/kafka
chown -R cp-kafka:confluent /kafkadata/kafka
chmode 710 /kafkadata/kafka
启动Kafka集群:
sudo systemctl start confluent-zookeeper
sudo systemctl start confluent-kafka
sudo systemctl start confluent-schema-registry
确保Ef2重新启动后,Kafka必须自动启动。
sudo systemctl enable confluent-zookeeper
sudo systemctl enable confluent-kafka
sudo systemctl enable confluent-schema-registry
现在我们的kafka集群已经准备就绪。要检查系统主题列表,请运行以下命令。
kafka-topics --list --zookeeper localhost:2181
__confluent.support.metrics
设置Debezium:
在所有生产者节点上安装融合连接器和debezium MySQL连接器。
apt-get update
sudo apt-get install default-jre
wget -qO - https://packages.confluent.io/deb/5.3/archive.key | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://packages.confluent.io/deb/5.3 stable main"
sudo apt-get update && sudo apt-get install confluent-hub-client confluent-common confluent-kafka-connect-s3 confluent-kafka-2.12
配置:
/etc/kafka/connect-distributed.properties在所有生产者节点上编辑,以使我们的生产者将以分布式方式运行。
-- On all the connector nodes
bootstrap.servers=172.31.47.152:9092,172.31.38.158:9092,172.31.46.207:9092
group.id=debezium-cluster
plugin.path=/usr/share/java,/usr/share/confluent-hub-components
安装Debezium MySQL连接器:
confluent-hub install debezium/debezium-connector-mysql:latest
它会要求进行一些更改,只需Y为所有内容进行选择即可。
将分布式连接器作为服务运行:
vi /lib/systemd/system/confluent-connect-distributed.service
[Unit]
Description=Apache Kafka - connect-distributed
Documentation=http://docs.confluent.io/
After=network.target
[Service]
Type=simple
User=cp-kafka
Group=confluent
ExecStart=/usr/bin/connect-distributed /etc/kafka/connect-distributed.properties
TimeoutStopSec=180
Restart=no
[Install]
WantedBy=multi-user.target
启动服务:
systemctl enable confluent-connect-distributed
systemctl start confluent-connect-distributed
配置Debezium MySQL连接器:
创建一个mysql.json包含MySQL信息和其他格式选项的文件。
{
"name": "mysql-connector-db01",
"config": {
"name": "mysql-connector-db01",
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.server.id": "1",
"tasks.max": "3",
"database.history.kafka.bootstrap.servers": "172.31.47.152:9092,172.31.38.158:9092,172.31.46.207:9092",
"database.history.kafka.topic": "schema-changes.mysql",
"database.server.name": "mysql-db01",
"database.hostname": "172.31.84.129",
"database.port": "3306",
"database.user": "bhuvi",
"database.password": "my_stong_password",
"database.whitelist": "proddb,test",
"internal.key.converter.schemas.enable": "false",
"key.converter.schemas.enable": "false",
"internal.key.converter": "org.apache.kafka.connect.json.JsonConverter",
"internal.value.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"internal.value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState"
"transforms.unwrap.add.source.fields": "ts_ms",
}
}
“ database.history.kafka.bootstrap.servers”-Kafka服务器IP。
“ database.whitelist”-获取CDC的数据库列表。
key.converter和value.converter以及转换参数-默认情况下,Debezium输出将具有更详细的信息。但是我不想要所有这些信息。我只对获取新行和插入时的时间戳感兴趣。
如果您不想自定义任何内容,则只需在 database.whitelist
注册MySQL连接器:
curl -X POST -H "Accept: application/json" -H "Content-Type: application/json" http://localhost:8083/connectors -d @mysql.json
检查状态:
curl GET localhost:8083/connectors/mysql-connector-db01/status
{
"name": "mysql-connector-db01",
"connector": {
"state": "RUNNING",
"worker_id": "172.31.94.191:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "172.31.94.191:8083"
}
],
"type": "source"
}
测试MySQL使用者:
现在将内容插入到中的任何表中proddb or test(因为我们只列出了这些数据来捕获CDC。
use test;
create table rohi (id int),
fn varchar(10),
ln varchar(10),
phone int );
insert into rohi values (2, 'rohit', 'ayare','87611');
我们可以从Kafker经纪人那里获得这些价值。打开任何一个kafka节点,然后运行以下命令。
为此,我更喜欢融合cli。默认情况下它将不可用,因此请手动下载。
curl -L https://cnfl.io/cli | sh -s -- -b /usr/bin/
监听以下主题:
mysql-db01.test.rohi
这是servername.databasename.tablename
服务器名的组合(您在mysql json文件中作为服务器名提到了此名称)。
confluent local consume mysql-db01.test.rohi
----
The local commands are intended for a single-node development environment
only, NOT for production usage. https://docs.confluent.io/current/cli/index.html
-----
{"id":1,"fn":"rohit","ln":"ayare","phone":87611,"__ts_ms":1576757407000}
在所有生产者节点中设置S3接收器连接器:
我想将此数据发送到S3存储桶。因此,您必须具有可访问目标S3存储桶的EC2 IAM角色。或安装awscli和配置访问权限和密钥(但不建议这样做)
创建s3.json文件。
{
"name": "s3-sink-db01",
"config": {
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"s3.bucket.name": "bhuvi-datalake",
"name": "s3-sink-db01",
"tasks.max": "3",
"s3.region": "us-east-1",
"s3.part.size": "5242880",
"s3.compression.type": "gzip",
"timezone": "UTC",
"locale": "en",
"flush.size": "10000",
"rotate.interval.ms": "3600000",
"topics.regex": "mysql-db01.(.*)",
"internal.key.converter.schemas.enable": "false",
"key.converter.schemas.enable": "false",
"internal.key.converter": "org.apache.kafka.connect.json.JsonConverter",
"format.class": "io.confluent.connect.s3.format.json.JsonFormat",
"internal.value.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"internal.value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"partitioner.class": "io.confluent.connect.storage.partitioner.HourlyPartitioner",
"path.format": "YYYY/MM/dd/HH",
"partition.duration.ms": "3600000",
"rotate.schedule.interval.ms": "3600000"
}
}
“topics.regex”: “mysql-db01”-它只会从带有mysql-db01前缀的主题中发送数据。在我们的例子中,所有与MySQL数据库相关的主题都将以该前缀开头。
“flush.size”-仅在存储了如此多的记录之后,数据才会上传到S3。或在”rotate.schedule.interval.ms”此期间之后。
注册此S3接收器连接器:
curl -X POST -H "Accept: application/json" -H "Content-Type: application/json" http://localhost:8083/connectors -d @s3
检查状态:
curl GET localhost:8083/connectors/s3-sink-db01/status
{
"name": "s3-sink-db01",
"connector": {
"state": "RUNNING",
"worker_id": "172.31.94.191:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "172.31.94.191:8083"
},
{
"id": 1,
"state": "RUNNING",
"worker_id": "172.31.94.191:8083"
},
{
"id": 2,
"state": "RUNNING",
"worker_id": "172.31.94.191:8083"
}
],
"type": "sink"
}
测试S3同步:
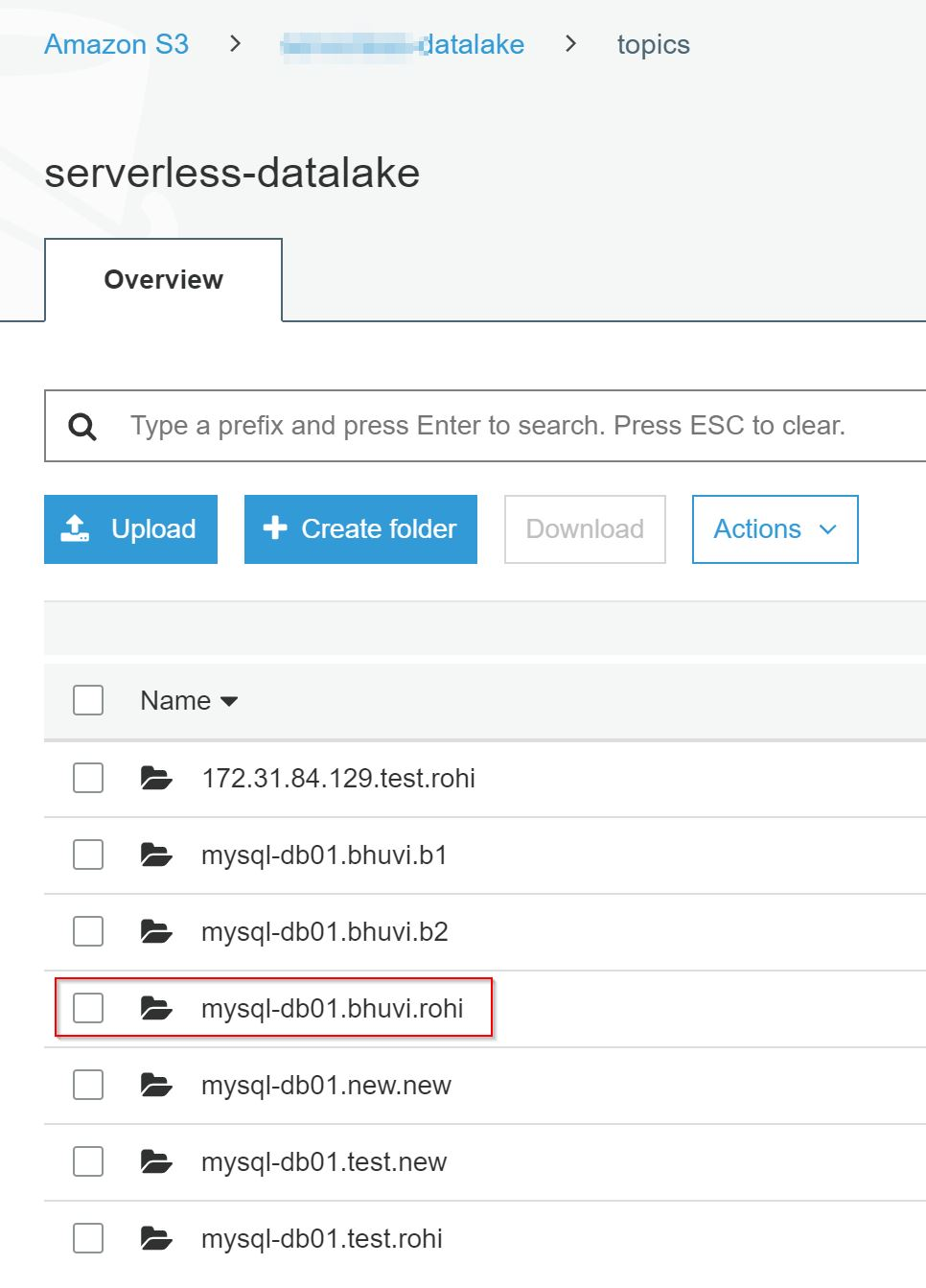

将10000行插入到rohi表中。然后检查S3存储桶。它将使用GZIP压缩以JSON格式保存数据。还在HOUR明智的分区中。
更多调优:
- 复制因子是数据持久性的另一个主要参数。
- 尽可能使用内部IP地址。
- 默认情况下,debezium每个主题使用1个分区。您可以根据工作负载进行配置。但是需要更多的分区。
参考文献:
1. 通过融合生产设置Kafka
2. 如何选择分区数
3. Kafka的打开文件描述符
4. AWS中的Kafka最佳实践
5. Debezium文档
6. 使用SMT自定义Debezium输出
来源:https://thedataguy.in/build-production-grade-debezium-with-confluent-kafka-cluster/